Beginners Guide to Pathfinding Algorithms
By ai-depot | December 19, 2002
![]() Network & tree searches are important as a basis for AI in many contexts. This article provides a colourful introduction and explains the different search methods available. It also shows the evolution of A* over other search algorithms.
Network & tree searches are important as a basis for AI in many contexts. This article provides a colourful introduction and explains the different search methods available. It also shows the evolution of A* over other search algorithms.
Written by Senior Diablo.
Basic Search
Search methods aren’t the perfect solution for every problem, but with creative applications can solve many. If search is an appropriate solution, which of the many methods do you use? Which method is guaranteed to find the solution? Which is the most efficient?
The following psuedocode represents the most basic form of tree/network searching. It contains no heuristics or assumptions. It will be modified to demonstrate each of the search methods discussed.
Pseudocode:
This assumes that the following have been passed to the function
- A start node of the network or tree, denoted S
- A goal node, denoted G
This also assumes there is a tree or network from which contains the paths to be followed.
create a list P
add the start node S, to P giving it one element
Until first path of P ends with G, or P is empty
extract the first path from P
extend the path one step to all neighbors creating X new paths
reject all paths with loops
add each remaining new path to P
If G found -> success. Else -> failure.
We’ll follow a simple example:
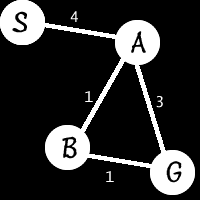
Each node is denoted with a letter. The start node is S the goal node is G. A and B are nodes representing intermediate destinations. Each line connecting two nodes represents the path which must be followed to arrive at that new node. Notice that each path has a number, or a weight, associated with it. This number can represent simple distance or travel difficulty (such as difficult terrain, for example) or travel time such as how long it takes to get there.
First, we pass the start node, S and the goal node G to our search function. S is added to the list first thing and then we enter the main loop.
S is extracted from the list and extended one step to each of its neighbors. The only neighbor S has is A so this results in one path, S->A, which is then added back into the list which now contains only that element (we removed S, remember?)
Next time through the loop, it extracts S->A and extends one step to each of A’s neighbors. This gives us three more paths: S->A->S, S->A->B and S->A->G. S->A->S is a loop, so we discard it. This leaves us with S->A->B and S->A->G each of which are pushed into the list. The list now contains two elements, the ones we just added.
The next iteration proceeds in a similar manner: S->A->B is extracted and extended to it’s neighbors, giving us: S->A->B->A and S->A->B->G. The first is a loop (see A in there twice?) and so is eliminated. S->A->B->G is added to the list. The list now contains two elements: S->A->G and S->A->B->G
At last, we’re done. The loop condition checks the first element of the list which is S->A->G. Since the last part of this path ends at the destination, G, it jumps to the end. Having reached G, it returns success.
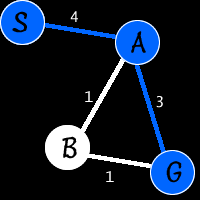
Is this the most efficient method? That depends… It looks like it, I mean there are two possible paths: S->A->G which only has two steps (S to A and A to G) and S->A->B->G which has three (S to A, A to B, and B to G). It has fewer steps so its the shortest path, right?
Not necessarily: If you add up the weight of each possible path (S->A->G and S->A->B->G) you get 7 for S->A->G and only 6 for S->A->B->G. So, the second is actually shorter even though the former has fewer steps. Which one you want is up to you. This most basic method will give you the fewest number of steps, but not necessarily the lowest-cost (or shortest) path.
Another possibility we can explore is this:
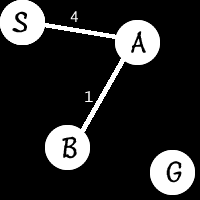
Notice there is no possible path from S to G. What will happen in this case is:
- S will be expanded to S->A
- S->A will be expanded to S->A->B
- S->A->B cannot be expanded, so the list will remain empty
The loop will end because the list is empty, G has not been found so it will return failure.
Next we’ll make our search method a little more complicated and explore DFS, BFS and random search.
Tags: none
Category: tutorial |
