Beginners Guide to Pathfinding Algorithms
By ai-depot | December 19, 2002
Blind Search
Assume you know nothing about the graph/tree/network/whatever being searched (I’m just going to call it a tree from now on because, once you reject all loops a graph or network is basically just a tree anyway. This is oversimplified, and there’s a mathematical proof of it, but that only complicates the issue). You dont know how many neighbors each node has until you get there. From starting node, S, you know what neighbors it has (say A and B) but you dont know how many neighbors A and B have until you get there.
Even not knowing things like that, DFS and BFS are guaranteed to find you a path if one exists.
BFS is fairly similar to the basic search I described previously. This uses a data structure called a queue. You add the newly formed paths to the back of the list. When you remove them to expand them, you remove them from the front.
create a queue P
add the start node S, to P giving it one element
Until first path of P ends with G, or P is empty
extract the first path from P
extend the path one step to all neighbors creating X new paths
reject all paths with loops
add each remaining new path to the BACK of P
If G found -> success. Else -> failure.
BFS explores the tree uniformly checks all paths one step away from the start, then two steps, then three, and so on.
DFS differs from BFS only in how the new paths are added to the list. In this case, it uses a stack rather than a queue. In a stack, new elements are added to the front of the list rather than the back, but when the remove the paths to expand them, you still remove them from the front. The result of this is that DFS explores one path, ignoring alternatives, until it either finds the goal or it cant go anywhere else.
create a stack P
add the start node S, to P giving it one element
Until first path of P ends with G, or P is empty
extract the first path from P
extend the path one step to all neighbors creating X new paths
reject all paths with loops
push each remaining new path to the FRONT of P
If G found -> success. Else -> failure.
For this example, we’ll have to make our graph a little more complicated to better demonstrate. I have left the weights off the node connections to make it a little more simple.
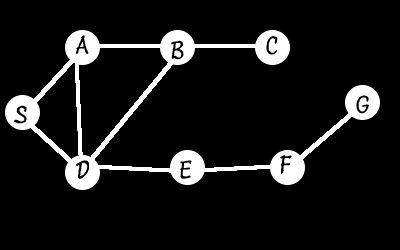
This example begins as the first one did: we add S to the list (in this case a stack). Then we enter the main loop:
S is removed and expanded to each neighbor resulting in the paths S->A and S->D which are then added to the FRONT of the list (the order of individual paths added is a matter of preference. For this exampl, I’m adding them so S->A is first and S->D is second).
S->A is extracted and expanded giving us: S->A->B, S->A->D, and S->A->S. S->A->S gives us a loop, so we reject it leaving us with the following list of paths: S->A->B, S->A->D, S->D
We extract S->A->B and expand it to the following: S->A->B->A (loop), S->A->B->C, S->A->B->D. Rejecting the loop and adding the others to our list gives our list the following contents: S->A->B->C, S->A->B->D, S->A->D, S->D
Next, we look at S->A->B->C and expand it one step which only takes us back to B in a loop. So, we reject it and move on - it was a dead end. Our list now contains: S->A->B->D, S->A->D, S->D
Expanding S->A->B->D adds only S->A->B->D->E to our list, having ignored the three loops: S->A->B->D->S, S->A->B->D->A, and S->A->B->D->B.
Finally we’re in the home stretch. Over the next few passes through the loop it expands S->A->B->D->E to S->A->B->D->E->F and finally to S->A->B->D->E->F->G which gives us a path to our goal.
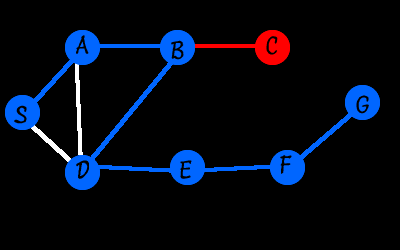
BFS and DFS are guaranteed to find a path to the goal (if one exists) but not necessarily the most efficient one. In this case, DFS gave us a path, but one that had an unnecessary detuour through A and B.
So if both are guaranteed to reach the destination, which one do we use? The answer to this depends on the tree itself. BFS is bad for those trees that have a high branching factor, that means that each node has a lot of neighbors use DFS for this. DFS is bad for those trees that have a lot of very long paths: use BFS for this.
So what do you do if you dont know the branching factor or the length of the paths? Use a non-deterministic random search. With this, you simply add the paths to random parts of the list. It doesn’t necessarily help, but it doesnt hurt either.
Next, A little knowledge can go a long way with Heuristics…
Tags: none
Category: tutorial |
