Getting Darwinian Evolution to Work
By ai-depot | February 12, 2003
![]() Suggests that Darwinian evolution has higher levels of abstraction and that explicitly exploiting these in attempts to evolve software on computers could allow programs of greater sophistication. A multi-layered system is proposed which uses the concept of ‘evolving evolvability’.
Suggests that Darwinian evolution has higher levels of abstraction and that explicitly exploiting these in attempts to evolve software on computers could allow programs of greater sophistication. A multi-layered system is proposed which uses the concept of ‘evolving evolvability’.
Written by Paul Almond.
Getting Darwinian Evolution to Work
Introduction
This article suggests that current methods of implementing Darwinian evolution on computers have severe limitations and proposes improvements in the way in which it is done.
It is suggested that the �evolvability� associated with data that has some meaning is a characteristic of the particular interpretation which that gives that data its meaning, so that evolvability is mainly a characteristic of the interpretation rather than the data: some interpretations will lead to high evolvability and useful progress by evolution algorithms and some interpretations will lead to low evolvability, with little useful progress.
The idea of a hierarchical system of machines is used, each layer in this system acting as an interpreter for the next layer by controlling its state transitions. It is proposed that each layer of software is evolved successively to produce an interpreter with high �evolvability� and that the utility of the particular data on a given layer should be evaluated, following mutation in an evolutionary process, by assessing the degree of progress observed in a large number of secondary evolution processes, each of which uses a different evaluation function, performed on the data in a next layer machine.
The proposed method involves evolving each layer to act as an interpreter for the layer above it and it is expected that the degree of sophistication with which each layer does this will increase as more layers are added, as the evolution process that generates each layer �benefits� from the evolvability that has already been attained in lower layers.
Problems with Existing Genetic Methods
Existing genetic algorithm techniques have not generated software of substantial complexity.
It seems intuitively apparent to me that mutating symbols in a computer program is unlikely to result in a complex system in any reasonable time. However, it seems that mutation of the ACTG symbols in biological genetic codes can lead to evolution of complex systems. Why is there this difference between our computer systems and biological systems?
I suggest that the main issue here is one of interpretation. Any data that is mutated is effectively a sequence of symbols that is subjected to interpretation. In the case of a high level computer program the symbols are the computer program and it is subject to interpretation by the rules of the computer language being used (provided by a language interpreter or compiler). In the case of DNA the sequence of As, Cs, Ts and Gs is interpreted by the underlying biochemistry, which provides a �machine architecture�.
The underlying architecture is needed to provide the sequence of symbols that is being mutated with its meaning. As an example, the sequence of symbols in the DNA that codes for construction of an organism only encodes for an organism when interpreted by the underlying biochemistry: without this it is just an arbitrary sequence of symbols.
I now make this suggestion:
The likelihood of a mutation on a sequence of symbols having a positive effect is determined by:
- The current complexity of the system described by the sequence of symbols.
- The architecture that is interpreting the sequence of symbols.
I suggest that this makes the interpretative architecture the most important influence on how quickly evolution of a sequence of symbols can progress and that most architectures devised by humans will only give any useful rate of evolution for systems of quite low complexity, the evolution process effectively grinding to a halt when a certain level of complexity is reached. (See figure 1)
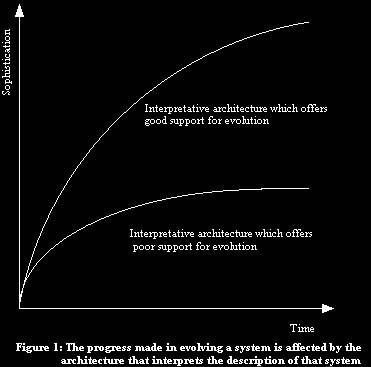
We could perhaps imagine an interpretative architecture designed to allow rapid evolution of the sequence of symbols that it interprets, but it is difficult to imagine actually designing such a thing.
Evolution in biological systems, however, seems to produce complex systems. How does evolution manage to produce complex systems? I suggest that the answer lies in the biochemistry that interprets the DNA - it must be a particular interpretative architecture that allows evolvability.
If we need an interpretative architecture that allows evolvability of the data that it interprets then we seem to have a problem here - how does such an interpretative architecture get there in the first place? Clearly, it must have evolved. This may seem to be a paradox - how can we have an interpretative architecture that allows evolvability to evolve when we need it in the first place to allow evolution?
I suggest that the answer is that evolution is not a process that is totally allowed or prohibited by the interpretative architecture, but, instead, that different architectures allow different degrees of evolution and that the architecture effectively imposes an upper limit on the complexity of the systems that can be evolved with it. The interpretative architecture in biochemistry is less complex than some of the systems that use it to evolve, so can actually evolve within the context of a cruder interpretative architecture that does not allow as much evolvability.
Here is what I think has happened in biological evolution:
A multi-layered system of interpretative architectures has evolved.
The bottom level of this system is the basic laws of physics. At the start there is nothing to do the interpreting except the laws of physics. Systems evolve that are interpreted by these laws. The laws of physics have not been designed with evolvability in mind and the process of evolution is extremely slow, with an effective upper limit on the sophistication of the systems that it can produce in any reasonable time.
This is inadequate for producing anything like complex animals, or even bacteria, but this is not what evolves. Although complex systems are not available, what can evolve is a second layer of interpretative architecture that is slightly better at allowing evolution to occur with the data that it interprets than the laws of physics. Evolution of data that is interpreted by this second layer now proceeds more rapidly and has a higher upper limit on complexity than is allowed by evolution within the context of the basic laws of physics. It still does not have a very rapid rate of evolution, or a very high upper limit on complexity, because limits were imposed by the context of the laws of physics in which it evolved, but it does not have to be very good. All it needs to be is better for evolution than the laws of physics. It can now be used to evolve a third layer of interpretation that is too complex to have evolved within the context of the laws of physics. This third layer of interpretation can now be
used to evolve a fourth layer of interpretation that is too complex to have evolved within the context of the laws of physics or the second interpretative layer.
This process continues, with successive layers of interpretative architecture evolving. Each time a new interpretative layer is added the rate of evolution and the upper limit on complexity both increase. The evolution process itself is evolving and highly complex organisms can ultimately be produced.
We need to use a process like this to evolve sophisticated computer software.
Tags: none
Category: essay |
