Machine Learning in Games Development
By ai-depot | September 26, 2002
![]() Explains the current perceptions of ML in the games industry, some of the techniques and implementations used in present and future games. A description about designing your very own learning agent is provided.
Explains the current perceptions of ML in the games industry, some of the techniques and implementations used in present and future games. A description about designing your very own learning agent is provided.
Written by Nick Palmer.
Machine Learning in Games Development
In this article, I shall outline the current perceptions of ‘Machine Learning’ in the games industry, some of the techniques and implementations used in current and future games, and then explain how to go about designing your very own ‘Learning Agent’.
The Games Industry
Machine Learning has been greeted with a certain amount of caution by games developers, and until recently, has not been used in any major games releases. Why is this — surely there must be potential demand for games that can learn — games that can adjust strategy to adapt to different opponents? There are several major reasons for the lack of enthusiasm which has, for a long time, been exhibited. Another question to be asked, is just how important is it for a game to ‘learn’? Is the average games player going to appreciate any significant advance in gameplay, or will all the effort be a waste of time and money? This — of course — depends on the game. Would Black & White have been half as successful if it wasn’t for the loveable creatures that could be taught, through kindness or cruelty, to mimic their master…?
Many games companies are currently looking at the possibility of making games that can match the player’s ability by altering tactics and strategy, rather than by improving the ability of opponents. This sounds similar to the standard ‘difficulty level’ feature which is hardly a rarity, but don’t be fooled - there are few games on the market which can uncover a player’s tactics and adapt to them. Even on the toughest difficulty settings of most games (FPS’s especially), most players have a routine, which if successful, will mean that they win more often than not. However, they would surely not be so smug if the AI could work out their favourite hiding places, or uncover their winning tactics and adapt to them! This could become a very important feature of future releases, as it would prolong game-life considerably.
Varieties of Learning
The greatest temptation for designers, is to create a false impression of learning. It is commonplace within the gaming industry to create cheating AI systems, and I suppose there can be few moral objections to this as it does simplify things a great deal. An impression of learning can be easily implemented by controlling the frequency of errors in tactical decisions made by the AI, and reducing them with ‘experience’ as the game is played. This creates a realistic illusion of an intelligent learning process, but cannot be used unless the desired behaviour is already known - in other words, this is useless for learning to counter player strategy.
Central to the process of learning, is the adaptation of behaviour in order to improve performance. Fundamentally, there are two methods of achieving this — directly (changing behaviour by testing modifications to it), and indirectly (making alterations to certain aspects of behaviour based on observations). There are positive and negative sides to each, but direct adaptation does have the advantage of not limiting behaviour, which means that ultimately, a better goal may be achievable.
Creating a Learning Agent
Having seen why it is desirable to create adaptable games, I shall now demonstrate the ways in which a learning system can be implemented in a game. As a basis for this subject, I shall use the example of a team-strategy based paintball game — which I am designing the AI for as part of the final year of my degree. The aim of the program is for a team of seven agents to capture the opponent’s flag and bring it back to their starting position. They must do this without being hit by the opposing team’s paintballs. So, what elements are involved in the tactics behind this type of game? Well for a start, I shall exclude the team strategy from my discussions, and concentrate on the individual agents — it is no good having a perfect strategy if the agents aren’t smart enough to survive on their own!
We must consider the factors which will influence an agents performance in the game. Terrain is an obvious start point, as this is all that stands between the two teams, so it must be used to the agent’s advantage. Secondly, there must be an element of stealth behind the behaviour of each agent, as otherwise it will be simple to undermine any tactics used during the game by simply picking off the naïve agents one-by-one.
A learning agent is composed of a few fundamental parts : a learning element, a performance element, a curiosity element (or ‘problem generator’), and a performance analyser ( or ‘critic’). The learning element is the part of the agent which modifies the agent’s behaviour and creates improvements. The performance element is responsible for choosing external actions based on the percepts it has received (percepts being information that is known by the agent about its environment). To illustrate this, consider that one of our agents is in the woods playing paintball. He is aware of an opposing paintballer nearby. This would be the percept that the agent responds to, by selecting an action - moving behind a tree. This choice of action is made by the performance element.
The performance analyser judges the performance of the agent against some suitable performance measure (which in this case could be how close the agent is to being hit by the enemy, or how many enemies have been hit). The performance must be judged on the same percepts as those received by the performance element - the state of affairs ‘known’ to the agent. When the analysis of performance has been made, the agent must decide whether or not a better performance could be made in the future, under the same circumstances. This decision is then passed to the learning element, which decides on the appropriate alteration to future behaviour, and modifies the performance element accordingly.
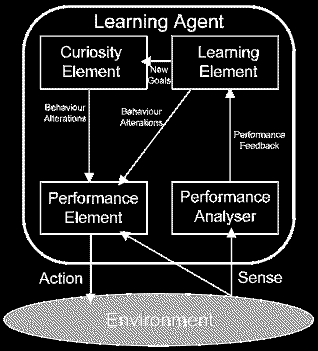
So far, so good. But then how do we make sure that the agent advances in its learning, and doesn’t merely confine itself to previously observed behaviour? (See the section on Set Behaviour, below). This is dealt with by the curiosity element (so-called because it searches for a better solution) which has a knowledge of the desirable behaviour of the agent (i.e. it knows that being shot is not desirable, and that finding the opponent’s flag is!). To achieve optimal performance, this element will pose new challenges to the agent in an attempt to prevent (bad) habits developing. To understand the benefits of this, consider a paintballer who is hiding behind a tree. From his past experience, he knows that he is safe to stay where he is, and this would result in an adequate performance. However, the curiosity element kicks in, and suggests that he makes a break from his cover and heads to a nearby tree which is closer to the enemy flag. This may result in the agent ultimately being shot at, but could also achieve a more desirable goal. It is then up to the performance analyser and the learning element to consider whether there is a benefit to this change in strategy.
At this point, it would be a good idea to mention the fact that this style of learning is known as reinforcement learning, which means that agent can see the result of its actions, but is not told directly what it should have done instead. This means that the agent must use, what is really trial and error, to evaluate its performance and learn from mistakes. The advantage to this is that there is no limitation on the behaviour, other than the limit to alterations suggested through the curiosity element. If after each action, the agent was told what its mistake was and how it should correct its behaviour, then the desired behaviour must already be understood, and therefore the learning is, in effect, obsolete.
As the learning agent is ultimately part of a game, it must not be left simply to work out for itself how to play. The agents must be imparted with a fair degree of prior knowledge about the way to behave. In the case of paintball, this could include methods for avoiding fire by using cover, which may later be adapted during the learning process. Many games developers use learning algorithms in their games to create better computer player AI, but the resulting AI is then ‘frozen’ before shipping.
I shall not go into the many algorithms which can be used to implement learning here, but they are well documented elsewhere, and can be found on the web. Decision trees are widely believed to be a good method of ‘reasoning’ - as are belief networks and neural networks, but these are beyond the scope of this article.
Problems with Learning
Despite the obvious potential that learning has to offer the gaming world, it must be used carefully to avoid certain pitfalls. Here are but a few of the problems commonly encountered when constructing a Learning AI:
- Mimicking Stupidity - When teaching an AI by copying a human player’s strategy, you may find that the computer is taught badly. This is more than likely when the player is unfamiliar with a game. In this situation, a reset function may be required to bring the AI player back to its initial state, or else a minimum level must be imposed on the computer player to prevent its performance dropping below a predetermined standard.
- Overfitting - This can occur if an AI agent is taught a certain section of a game, and then expected to display intelligent behaviour based on its experience. Using a FPS as an example, an agent which has learnt from its experience over one level will encounter problems when attempting a new level, as it may not have learnt the correct ‘lessons’ from its performance. If it has found that when opening doors, it has been able to escape the line of fire by diving behind a wall to its left, it will assume that this is a generalized tactic. As you can imagine, this could lead to amusing behavioural defects if not monitored in the correct way…
- Local Optimality - When choosing a parameter on which the agent is to base its learning, be sure to choose one which has no dependency on earlier actions. As an example, take a snow-boarding game. The agent learns, through the use of an optimization algorithm, the best course to take down the ski slope, using its rotation as a parameter. This may mean that a non-optimal solution is reached, in which any small change cannot improve performance. Think about the data being stored - a sequence of rotations clockwise and anticlockwise. An alteration to a rotation in the first half of the run may lead to a better time over the course in the long run, but in the short-run, could cause a horrific crash further down the slope, as the rest of the rotations are now slightly off course!
- Set Behaviour - Once an agent has a record of its past behaviour and the resulting performance analysis, does it stick to the behaviour which has been successful in the past, or does it try new methods in an attempt to improve? This is a problem which must be addressed or else an agent may either try to evaluate every possible behaviour, or else stick to one without finding the optimal solution.
Conclusion
Having looked at possible applications for learning, and seen some of the problems associated with it, it seems that there is great potential for learning in games, but it must be used with caution. The majority of games have little use for any kind of learning techniques - except in the development and testing stages. Despite the price of developing this kind of software, it looks as if learning will have a large part to play in the next generation of games.
References
- Rabin, Steve : AI Programming Wisdom - Charles River Media, INC. 2002
- http://www.cs.inf.shizuoka.ac.jp/~iida/CG98-CFP.html
- http://www.etl.go.jp/etl/suiron/~ianf/cg2000/index.html
- Russell, Stuart and Norvig, Peter : Artificial Intelligence ‘A Modern Approach’ - Prentice Hall 1995
- http://forum.swarthmore.edu/~jay/learn-game/index.html
- http://www.cris.com/~swoodcoc/ai.html
- http://satirist.org/learn-game/
Written by Nick Palmer.
Tags: none
Category: essay |
