Minimax Explained
By ai-depot | July 28, 2002
Optimisations
Optimisation
However only very simple games can have their entire search tree generated in a short time. For most games this isn’t possible, the universe would probably vanish first. So there are a few optimizations to add to the algorithm.
First a word of caution, optimization comes with a price. When optimizing we are trading the full information about the game’s events with probabilities and shortcuts. Instead of knowing the full path that leads to victory, the decisions are made with the path that might lead to victory. If the optimization isn’t well choosen, or it is badly applied, then we could end with a dumb AI. And it would have been better to use random moves.
One basic optimization is to limit the depth of the search tree. Why does this help? Generating the full tree could take ages. If a game has a branching factor of 3, which means that each node has tree children, the tree will have the folling number of nodes per depth:
| Depth | Node Count |
| 0 | 1 |
| 1 | 3 |
| 2 | 9 |
| 3 | 27 |
| … | .. |
| n | 3^n |
The sequence shows that at depth n the tree will have 3^n nodes. To know the total number of generated nodes, we need to sum the node count at each level. So the total number of nodes for a tree with depth n is sum (0, n, 3^n). For many games, like chess that have a very big branching factor, this means that the tree might not fit into memory. Even if it did, it would take to long to generate. If each node took 1s to be analyzed, that means that for the previous example, each search tree would take sum (0, n, 3^n) * 1s. For a search tree with depth 5, that would mean 1+3+9+27+81+243 = 364 * 1 = 364s = 6m! This is too long for a game. The player would give up playing the game, if he had to wait 6m for each move from the computer.
The second optimization is to use a function that evaluates the current game position from the point of view of some player. It does this by giving a value to the current state of the game, like counting the number of pieces in the board, for example. Or the number of moves left to the end of the game, or anything else that we might use to give a value to the game position.
Instead of evaluating the current game position, the function might calculate how the current game position might help ending the game. Or in another words, how probable is that given the current game position we might win the game. In this case the function is known as an estimation function.
This function will have to take into account some heuristics. Heuristics are knowledge that we have about the game, and it can help generate better evaluation functions. For example, in checkers, pieces at corners and sideways positions can’t be eaten. So we can create an evaluation function that gives higher values to pieces that lie on those board positions thus giving higher outcomes for game moves that place pieces in those positions.
One of the reasons that the evaluation function must be able to evalute game positions for both players is that you don’t know to which player the limit depth belongs.
However having two functions can be avoided if the game is symetric. This means that the loss of a player equals the gains of the other. Such games are also known as ZERO-SUM games. For these games one evalution function is enough, one of the players just have to negate the return of the function.
The revised algorithm is described in Listing 2.
MinMax (GamePosition game) { return MaxMove (game); } MaxMove (GamePosition game) { if (GameEnded(game) || DepthLimitReached()) { return EvalGameState(game, MAX); } else { best_move < - {}; moves <- GenerateMoves(game); ForEach moves { move <- MinMove(ApplyMove(game)); if (Value(move) > Value(best_move)) { best_move < - move; } } return best_move; } } MinMove (GamePosition game) { if (GameEnded(game) || DepthLimitReached()) { return EvalGameState(game, MIN); } else { best_move <- {}; moves <- GenerateMoves(game); ForEach moves { move <- MaxMove(ApplyMove(game)); if (Value(move) > Value(best_move)) { best_move < - move; } } return best_move; } }
Even so the algorithm has a few flaw, some of them can be fixed while other can only be solved by choosing another algorithm.
One of flaws is that if the game is too complex the answer will always take too long even with a depth limit. One solution it limit the time for search. If the time runs out choose the best move found until the moment.
A big flaw is the limited horizon problem. A game position that appears to be very good might turn out very bad. This happens because the algorithm wasn’t able to see that a few game moves ahead the adversary will be able to make a move that will bring him a great outcome. The algorithm missed that fatal move because it was blinded by the depth limit.
Speeding the algorithm
There are a few things can still be done to reduce the search time. Take a look at figure 2. The value for node A is 3, and the first found value for the subtree starting at node B is 2. So since the B node is at a MIN level, we know that the selected value for the B node must be less or equal than 2. But we also know that the A node has the value 3, and both A and B nodes share the same parent at a MAX level. This means that the game path starting at the B node wouldn’t be selected because 3 is better than 2 for the MAX node. So it isn’t worth to pursue the search for children of the B node, and we can safely ignore all the remaining children.
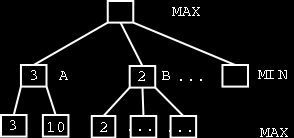
Figure 2: Minimax search showing branches that can be cuttoff.
This all means that sometimes the search can be aborted because we find out that the search subtree won’t lead us to any viable answer.
This optimization is know as alpha-beta cuttoffs and the algorithm is as follows:
- Have two values passed around the tree nodes:
- the alpha value which holds the best MAX value found;
- the beta value which holds the best MIN value found.
- At MAX level, before evaluating each child path, compare the returned value with of the previous path with the beta value. If the value is greater than it abort the search for the current node;
- At MIN level, before evaluating each child path, compare the returned value with of the previous path with the alpha value. If the value is lesser than it abort the search for the current node.
The Listing 3 shows the full pseudocode for MinMax with alpha-beta cuttoffs.
MinMax (GamePosition game) { return MaxMove (game); } MaxMove (GamePosition game, Integer alpha, Integer beta) { if (GameEnded(game) || DepthLimitReached()) { return EvalGameState(game, MAX); } else { best_move < - {}; moves <- GenerateMoves(game); ForEach moves { move <- MinMove(ApplyMove(game), alpha, beta); if (Value(move) > Value(best_move)) { best_move < - move; alpha <- Value(move); } // Ignore remaining moves if (beta > alpha) return best_move; } return best_move; } } MinMove (GamePosition game) { if (GameEnded(game) || DepthLimitReached()) { return EvalGameState(game, MIN); } else { best_move < - {}; moves <- GenerateMoves(game); ForEach moves { move <- MaxMove(ApplyMove(game), alpha, beta); if (Value(move) > Value(best_move)) { best_move < - move; beta <- Value(move); } // Ignore remaining moves if (beta < alpha) return best_move; } return best_move; } }
How better does a MinMax with alpha-beta cuttoffs behave when compared with a normal MinMax? It depends on the order the search is searched. If the way the game positions are generated doesn’t create situations where the algorithm can take advantage of alpha-beta cutoffs then the improvements won’t be noticible. However, if the evaluation function and the generation of game positions leads to alpha-beta cuttoffs then the improvements might be great.
Tags: none
Category: tutorial |

August 18th, 2007 at 6:33 pm
I just want to say thank you for writing this article and that it has helped me alot in my studies at time of writing.
September 16th, 2007 at 7:53 am
For me too, thanks Paulo.
October 25th, 2007 at 11:20 pm
Thank you for such simple yet elegant explanation.
January 9th, 2008 at 4:27 pm
neeeeeeeed your help
January 29th, 2008 at 12:04 pm
I want a chess source code using minimax alghoritm. you explaind checkers game.please help me.thank you
February 13th, 2008 at 9:13 am
Thank you
it is very useful
March 25th, 2008 at 5:08 pm
[…] game theory and, in a broader sense, decision theory. Most AI programmers who are familiar with his minimax model also know that one of the requisite premises of applying it is perfect knowledge of the game […]
April 19th, 2008 at 5:51 am
is it possible for 4 players
May 9th, 2008 at 4:04 am
Thanks a lot. You really helped me out. I’ve had spent hours reading an incorrect translation of Russell and Norvig’s AI book without success. Your site helped me.
June 11th, 2008 at 3:31 pm
I want to impelement Othello with c#,but I can’t
write c# code for minimax and alpha-beta.
please help me.
thanks
July 2nd, 2008 at 10:04 am
Thanks for the good explaination
July 2nd, 2008 at 10:11 am
sorry for two messages. One thing which would have been good to add, is the scoring on your tic tac toe game. showing which decision would have been made given the search depth of 2.
Otherwise, a really great explanation
July 2nd, 2008 at 2:01 pm
Very informative. Aside from the not-so-uncommon typo or grammatical error, a good read. This helped me with my AI project :)